
Setup a Slack report per squad in less than 30 minutes
No credit card required
Costory
APP
10:49 AM
👋 Hey Platform team — your January Cost Digest is ready.
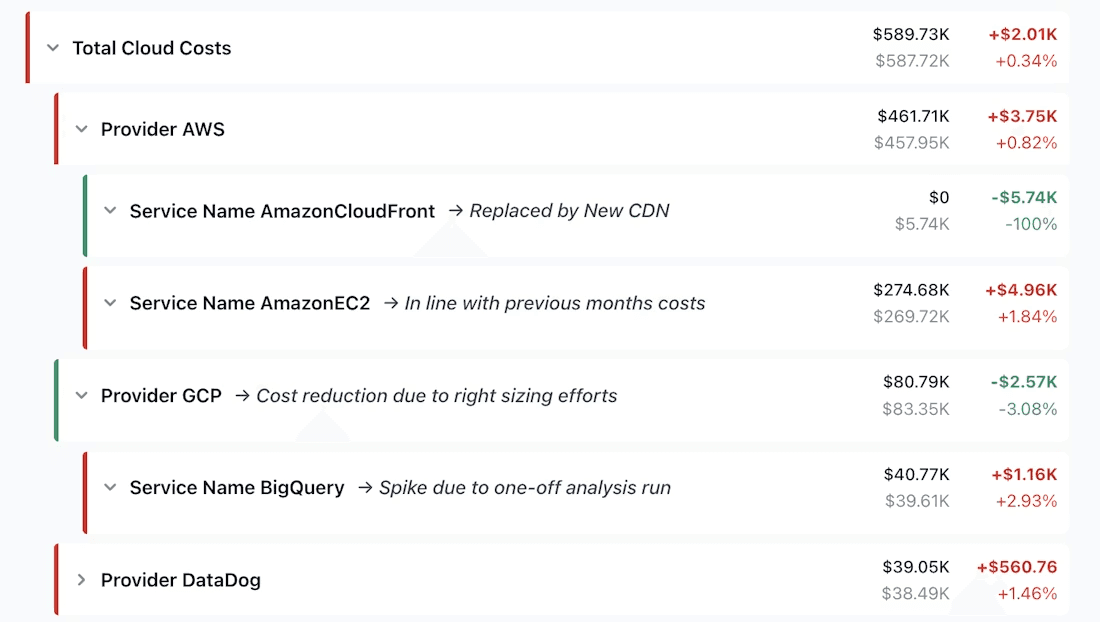
Total: $531K → $589K (+$57K · +10.8%)
CloudFront +$8.2K — 52% more CDN requests
Claude Opus +$3.8K — summarization pipeline scaled up on the 21th
Databricks +$12.4K — Expected as part of client Acme new setup
Anthropic API +$8.2K — 3 agentic workflows launched
Open full digest →
👀 4
👍 6
🔥 3



















Your time matters
Reclaim time with
FinOps automation
You could build this yourself. But your backlog is full. Costory gets you there faster, cheaper, and maintains it for you.
Then ask Billy — Costory's AI assistant — to explain the context. Works in Slack, or directly in Cursor via MCP.

Live in: ~30 minutes
Automated Slack cost reports for every Eng teams
Native AWS, GCP, Azure and LLM providers integration
AI detects your teams' scope automatically
Weekly Slack report per team. Not another dashboard to check ;)
Live in: ~30 minutes
Your cloud & LLM bills, explained in plain English
ML-powered: time series, NLP, and root cause analysis
Detailed markdown report for infra teams
CTO-friendly summary sent automatically via Slack
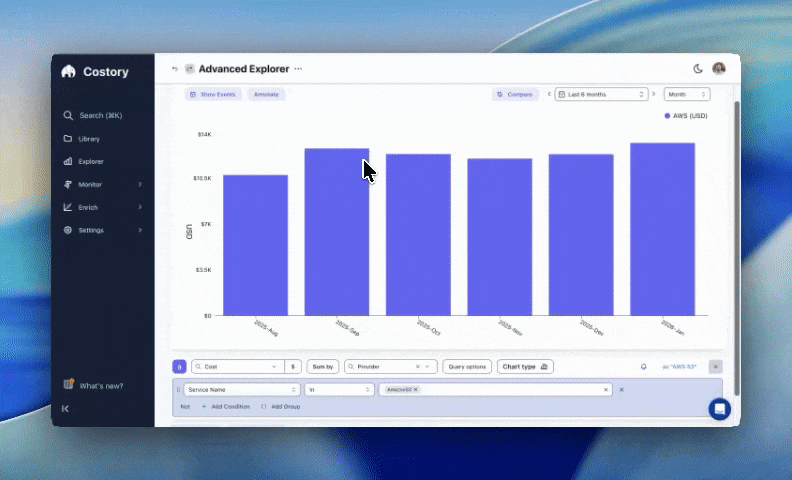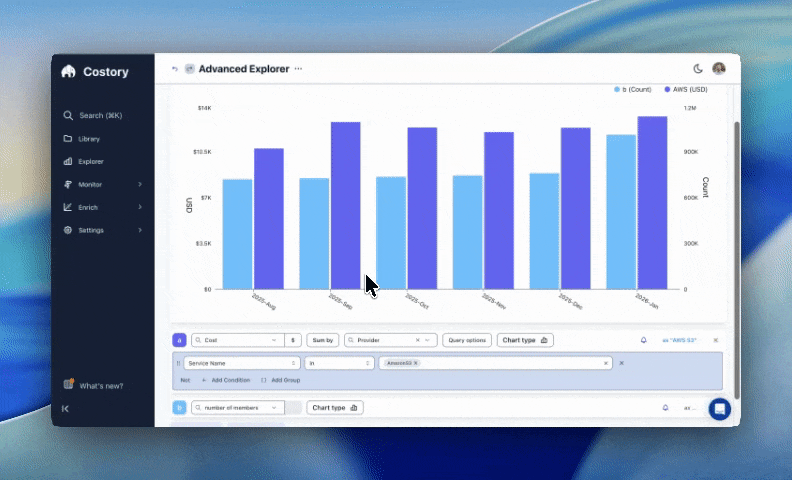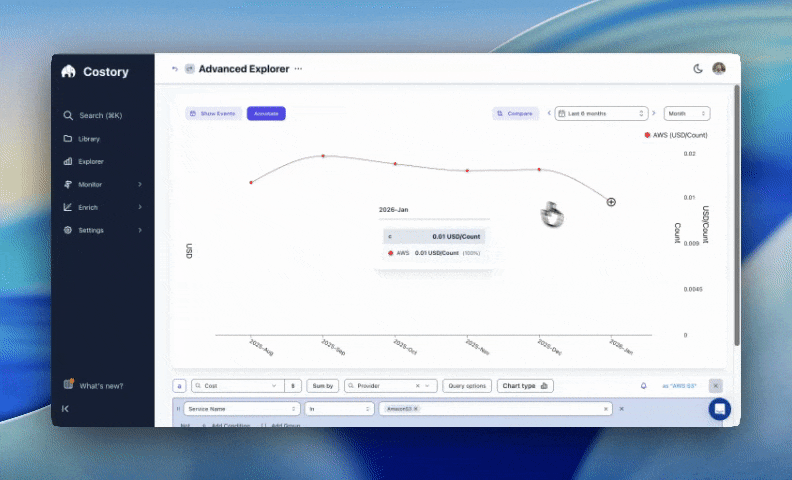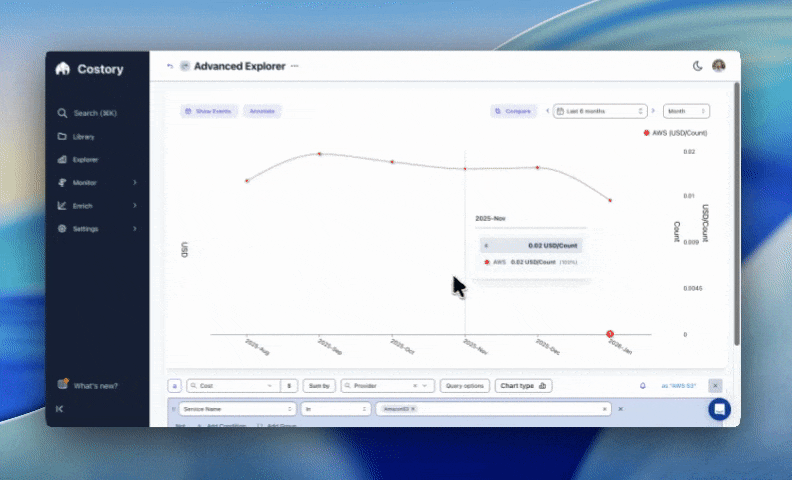
Live in: ~2 hours
A semantic layer for your cloud & LLM bills
Link GitHub deploys & CI/CD events
Ingest Datadog or observability metrics
Track Unit Economics (cost per client, cost per user...)
Live in: ~30 minutes
Explain cost to non-technical colleagues
Pre-Built FinOps Templates to Get Started in Minutes
Map costs by feature, tribe, clients. Allocations finance will understand
MCP (Claude, Cursor…), Looker and FP&A integrations

A note from the founding team
Why we built Costory
We built Costory because, honestly, we were tired.
Tired of being the Designated FinOps — that one SRE or infra lead pulled into every cost fire. "Why did the bill spike?" "Who's burning all the GPUs?" "Is this S3 bucket… normal?"
And every time, the same problem: billing logs know nothing. The real answers live in Slack threads, tribal knowledge, and whatever's in your head.
Your options were terrible: either build an internal tool you'll never have time to maintain, or pay a FinOps vendor priced for enterprises.
So we built Costory to share the load.
It filters the noise, spots what matters, and gives you investigation leads instead of raw alerts. It connects billing with GitHub PRs, Datadog usage, and your actual stack context — then uses AI to explain anomalies clearly (even to the CFO).
It's the FinOps assistant infra teams have always needed — and priced like something you can actually justify.
— Greg for the Costory team
Testimonials
Trusted by infra teams who don't have time
More cloud spend, more pricing complexity, less time to explain.



